
Napomena: Sljedeći članak će vam pomoći: Upoznajte Chameleon: Plug-and-Play okvir kompozicionog rezoniranja koji iskorištava mogućnosti velikih jezičnih modela
Nedavni veliki jezični modeli (LLM) za različite zadatke NLP-a napravili su izvanredne korake, a istaknuti primjeri su GPT-3PaLM, LLaMA, ChatGPT i nedavno predloženi GPT-4. Ovi modeli imaju ogromna obećanja za planiranje i donošenje odluka slično ljudskim budući da mogu riješiti različite zadatke u situacijama bez pokušaja ili uz pomoć nekoliko instanci. LLM-ovi pokazuju nove vještine, uključujući učenje u kontekstu, matematičko zaključivanje i zdravorazumsko razmišljanje. Međutim, LLM-i imaju ugrađena ograničenja, poput nemogućnosti korištenja vanjskih alata, pristupa trenutnim informacijama ili matematičkog zaključivanja s preciznošću.
Područje istraživanja koje je u tijeku usmjereno je na poboljšanje jezičnih modela s pristupom vanjskim alatima i resursima i istraživanje integracije vanjskih alata i plug-and-play modularnih strategija za rješavanje ovih ograničenja LLM-a. Nedavna istraživanja koriste LLM za izradu kompliciranih programa koji učinkovitije rješavaju probleme logičkog zaključivanja i iskorištavaju snažne računalne resurse za poboljšanje sposobnosti matematičkog zaključivanja. Na primjer, uz pomoć vanjskih izvora znanja i online tražilica, LLM-ovi mogu dobiti informacije u stvarnom vremenu i koristiti znanje specifično za domenu. Druga aktualna linija istraživanja, uključujući ViperGPT, Visual ChatGPT, VisProg i HuggingGPT, integrira nekoliko osnovnih modela računalnog vida kako bi LLM-u dala vještine potrebne za rješavanje problema vizualnog zaključivanja.
Unatoč značajnom napretku, današnji LLM-ovi prošireni alatima još uvijek nailaze na velike prepreke dok odgovaraju na upite iz stvarnog svijeta. Većina trenutnih tehnika ograničena je na uzak skup alata ili se oslanja na određene uređaje za određenu domenu, što otežava njihovu generalizaciju na različite upite. Lik 1 ilustrira ovo: “Koji je glavni uvjerljivi apel korišten u ovom oglasu?” 1) Pretpostavimo da reklamna slika ima tekstualni kontekst i pozovimo tekstualni dekoder da shvati semantiku za odgovor na ovaj upit; 2) pronađite pozadinske informacije kako biste objasnili što je “uvjerljiva privlačnost” i kako se različite vrste razlikuju; 3) doći do rješenja koristeći savjete iz ulaznog pitanja i privremene ishode iz ranijih faza; i 4) konačno, predstavite odgovor na način specifičan za zadatak.
S druge strane, dok odgovarate na pitanje “koja je životinjska koža prilagođena za preživljavanje na hladnim mjestima,” možda ćete trebati kontaktirati dodatne module, kao što je opis slike za analizu informacija o slici i web tražilica za prikupljanje znanja o domeni shvatiti znanstvenu terminologiju. Istraživači s UCLA i Microsoft Research pružaju Chameleon, plug-and-play okvir za rezoniranje kompozicije koji koristi ogromne jezične modele za rješavanje ovih problema. Chameleon može sintetizirati programe za stvaranje različitih alata za odgovore na više pitanja.
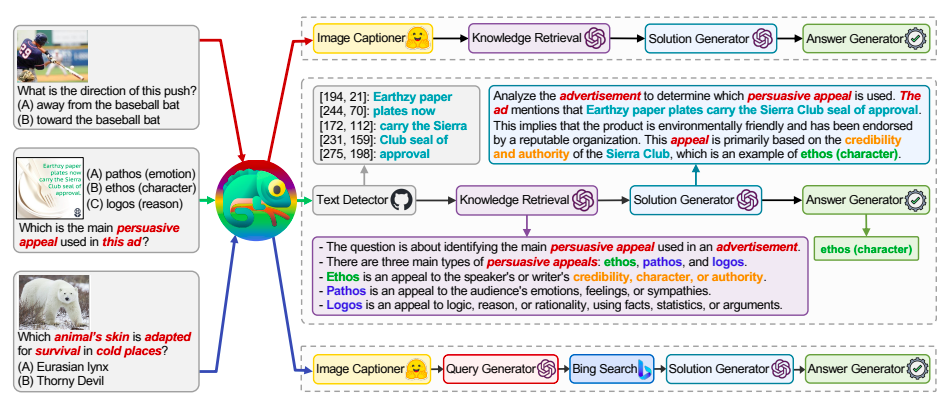
Chameleon je planer prirodnog jezika koji se temelji na LLM-u. Suprotno konvencionalnim metodama, koristi različite alate, kao što su LLMs, unaprijed izgrađeni modeli računalnog vida, online tražilice, Python funkcije i moduli temeljeni na pravilima dizajnirani za određeni cilj. Chameleon generira te programe pomoću mogućnosti učenja u kontekstu LLM-a i ne treba nikakvu obuku. Planer može zaključiti ispravan redoslijed alata koje treba sastaviti i pokrenuti kako bi pružio konačni odgovor na upit korisnika, potaknut opisima svakog alata i primjerima korištenja alata.
Chameleon stvara programe koji nalikuju prirodnom jeziku, za razliku od ranijih pokušaja koji su pravili programe specifične za domenu. Ovi su programi manje skloni pogreškama, jednostavniji su za otklanjanje pogrešaka, lakši su za korisnike s malo znanja o programiranju i proširivi za uključivanje novih modula. Svaki modul u programu izvršava, obrađuje i sprema upit i kontekst, vraća odgovor koji je odabrao modul i modificira upit i pohranjeni kontekst za nadolazeće izvršavanje modula. Sastavljanjem modula kao sekvencijalnog programa, ažurirani upiti i prethodno predmemorirani kontekst mogu se koristiti tijekom izvođenja sljedećih modula. Na dva zadatka—ScienceQA i TabMWP—oni pokazuju Chameleonovu fleksibilnost i moć.
TabMWP je matematičko mjerilo koje uključuje brojne tablične kontekste, dok je ScienceQA multimodalno mjerilo za odgovore na pitanja koje obuhvaća mnoge formate konteksta i znanstvene teme. Učinkovitost Chameleonove sposobnosti da koordinira različite alate u različitim vrstama i domenama može se testirati pomoću ova dva mjerila. Posebno, Chameleon s GPT-4 postiže točnost od 86,54% na ScienceQA, nadmašujući najbolje prijavljeni model s nekoliko snimaka za faktor od 11,37%. Chameleon donosi poboljšanje 70,97% iznad CoT GPT-4 i 17.8% povećanja u odnosu na najsuvremeniji model na TabMWP koji koristi GPT-4 kao temeljni LLM, što rezultira ukupnom točnošću od 98,78%.
U usporedbi s prethodnim LLM-ovima kao što je ChatGPT, daljnja istraživanja sugeriraju da korištenje GPT-a4 kao planer pokazuje dosljedniji i logičniji odabir alata i može zaključiti vjerojatna ograničenja s obzirom na upute. Njihovi kratki doprinosi su sljedeći: (1) Oni stvaraju Chameleon, plug-and-play okvir za kompozicijsko razmišljanje, kako bi riješili inherentna ograničenja velikih jezičnih modela i preuzeli različite zadatke razmišljanja. (2) Učinkovito kombiniraju nekoliko tehnologija, uključujući LLM, modele komercijalne vizije, online tražilice, Python funkcije i module temeljene na pravilima, kako bi stvorili fleksibilan i prilagodljiv AI sustav koji odgovara na upite iz stvarnog svijeta. (3) Značajno unapređuju stanje tehnike demonstrirajući fleksibilnost i učinkovitost okvira na dva mjerila, ScienceQA i TabMWP. Kodna baza je javno dostupna na GitHubu.
